在二进制的蛮荒世界里
有最迷惑的漏洞和最险恶的防护
IDA 和 gdb 是忠实的伙伴
逻辑和决心是我们的武器
热爱是引路人
Hi, This is my first time to give a write-up in English. I attended TCTF 2019 last weekend and lucky enough to solve this lovely babyheap challenge 30mins before the game finished. Really enjoy this challenge and want to share it with more pwn players.
The challenge package contains 3 files: a 64bit ELF called babyheap, and two libraries ld-2.28.so and libc-2.28.so, seems that it is deployed under Ubuntu 18.10. If you’re using 16.04 or other versions of ubuntu, you certainly could run this binary with LD_PRELOAD, but my suggestion is setting up an 18.10 environment for debugging, because with libc6-dbg installed, you can get libc symbol and view the heap state easily. Meanwhile, the function offset from libc would be exactly the same as the target machine. Docker is a good option.
1 | Arch: amd64-64-little |
No surprise, all mitigations are presented, and as per its definition, this is a common note system challenge with the following menu:
1 | ===== Baby Heap in 2019 ===== |
Vulnerability: off-by-one null byte
It looks very familiar to me and I remember there was a similar babyheap challenge last year. I dropped them both in ida and look at the difference, then I identify the bug very soon. babyheap 2018 on the left, babyheap 2019 on the right. The change appears in update function, when it read the new content for an allocated chunk, it calls a function to get input.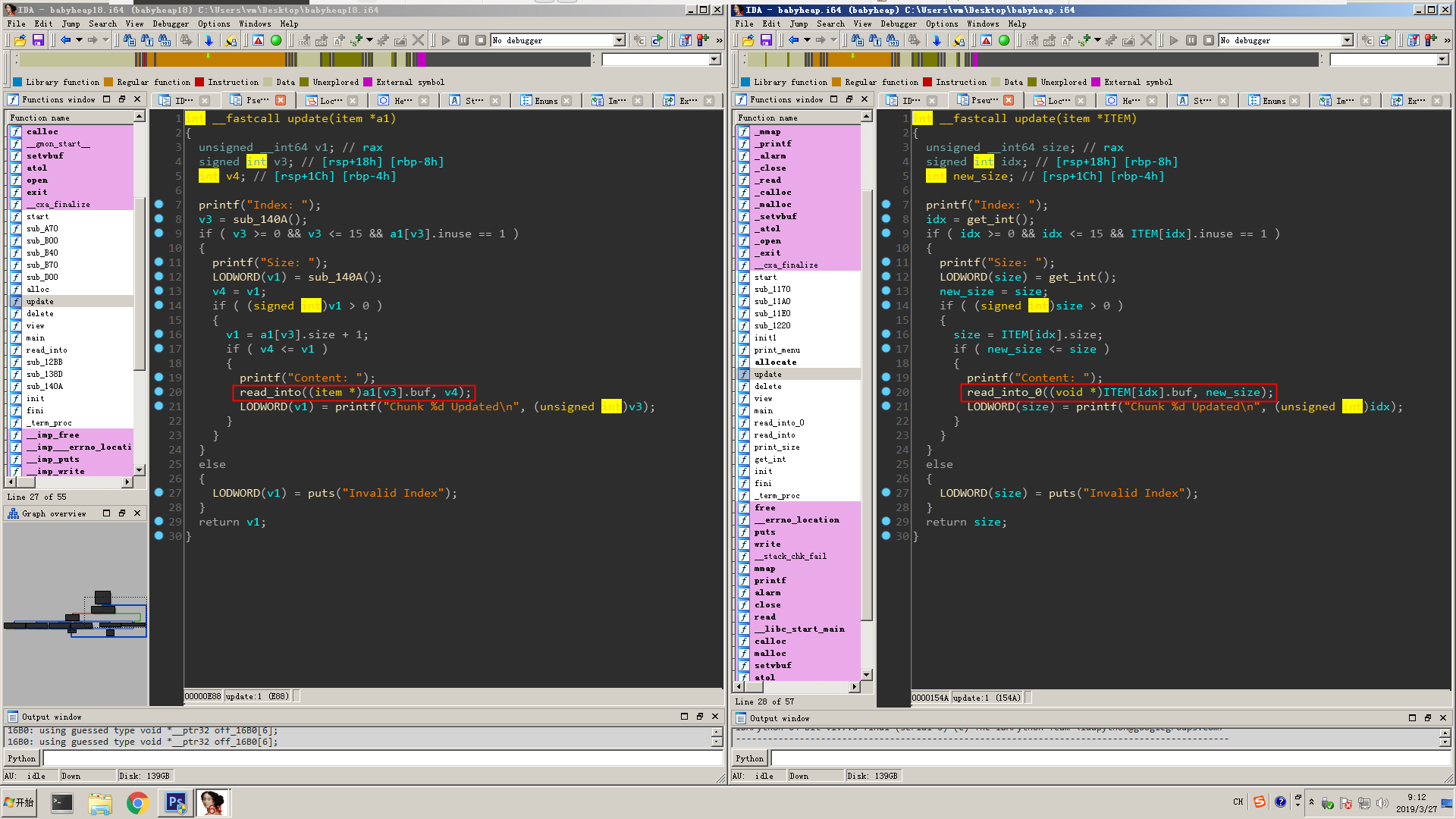 bug1
bug1
I followed into the function and, clearly, there is an off-by-one null byte bug in our 2019 challenge.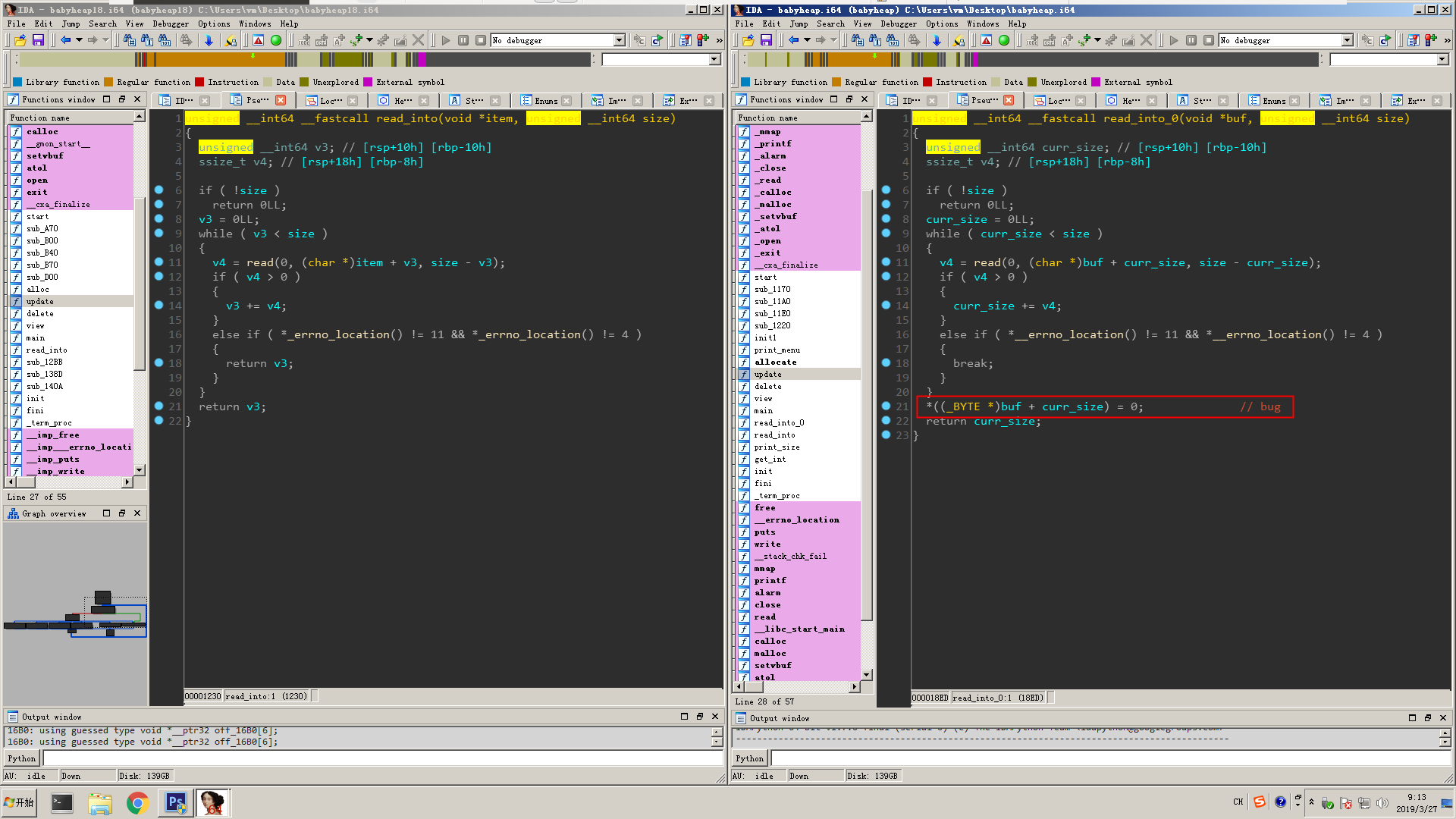 bug2
bug2
Beside that, another change occurs in the init function, which stealthily malloc a large chunk.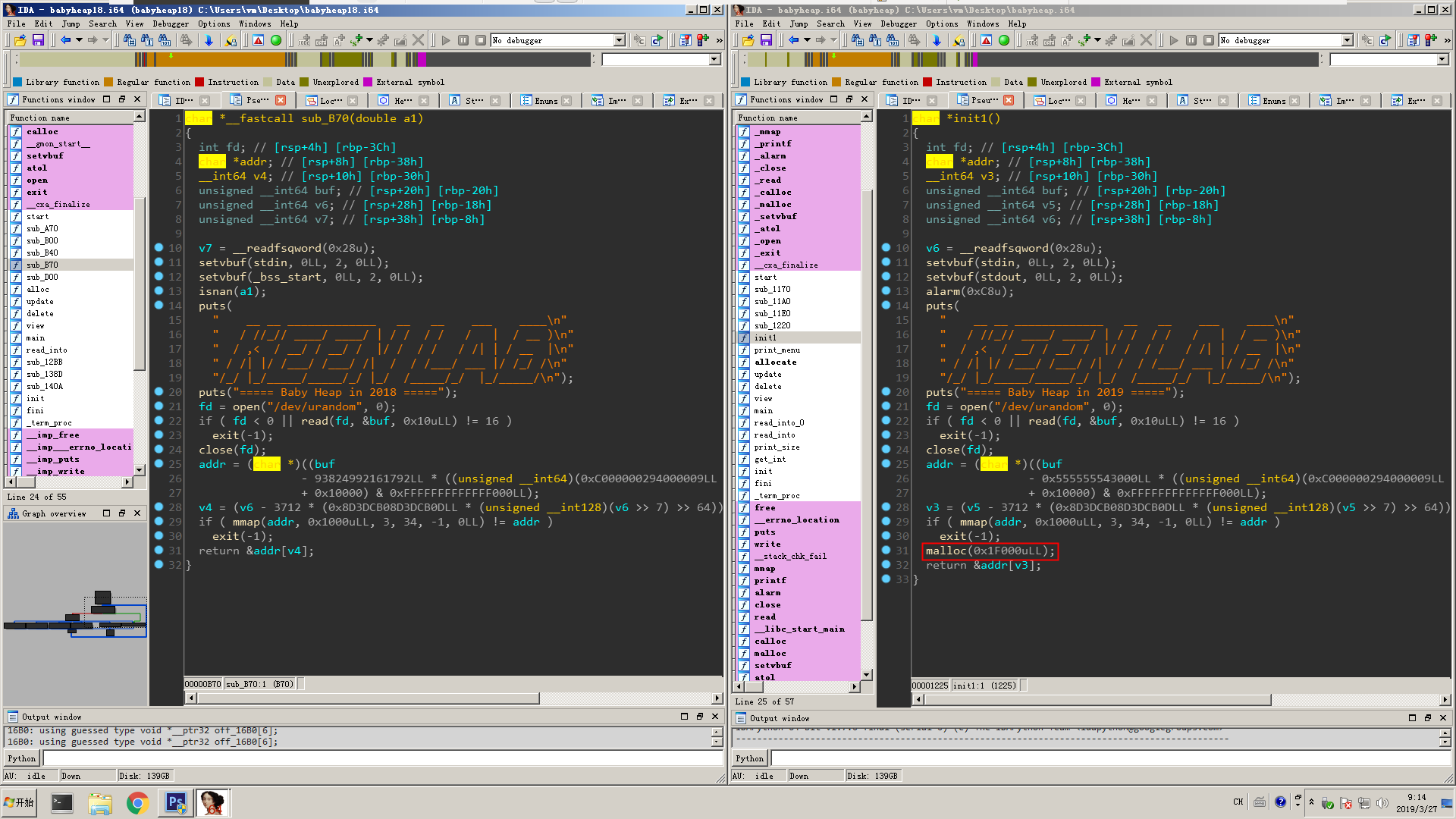 difference
difference
Other parts of the program are identical. BTW, babyheap 2018 was given an arbitrary off-by-one bug, we can overwrite one extra byte to the size of next chunk. A great writeup (in Chinese) can be found here: 0CTF 2018 Babyheap
Constrains and thoughts
OK, let’s wrap up the bug and constraints of this challenge:
- Bug: off-by-one null byte
- Constrains:
- list address randomization
- 0 < size < 88 (0x58)
- at max 16 items in the array
- libc 2.28 with tcache feature
In the init function, we can see the pointers of allocated items are not store at bss section as usual, but in a random memory space change each runtime. This prevents us to perform unlink attack technique or use the pointer list to perform arbitrary write. Also, it brings us some inconvenience when debugging, so I patch the file string /dev/urandom to ./addr\x00, and create an addr file with 16 bytes in the same directory. With this trick, the address of item array fixed on each run.
There are two known techniques about off-by-one null byte, we can find them on how2heap, the first one is house-of-einherjar, which results in getting a controlled pointer; the second is poison null byte, which leads to overlapping chunks. But both of techniques require the ability to malloc a small bin chunk, for example, we need to have a chunk size like 0x1xx, so that we could overwrite it to 0x100 and perform following steps. So mission one for us: figure out how to create a small bin chunk.
Small bin chunk
Remeber the suspicious malloc(0x1f000) in init function? After this operation, the top chunk becomes 0x1da0.
1 | pwndbg> heapinfoall |
Then I investigated the source code of malloc.c, it seems that when top chunk size is not enough for the malloc request, it will call malloc_consolidate() function and merge the freed chunk in fastbins! So, the idea is making a sequence of chunks on the fastbins, then consume the top chunk until small enough. Then any larger request will trigger malloc_consolidate() and make a small bin size chunk.
At first I worried about the tcache feature will prevent us from consuming the top chunk too far, however, it turns out tcache does not apply to calloc, once a chunk get into tcache bin, you cannot allocate it again with calloc. Also, we can shrink the top chunk size each time after allocation, this trick can help us to consume the top chunk quickly. Here is the heap state before triggering malloc_consolidate():
1 | (0x20) fastbin[0]: 0x0 |
Then we calloc(0x28), it triggers malloc_consolidate() and merage fastbin chunk into unsotredbin, creating a chunk in size of 0x210
1 | (0x20) fastbin[0]: 0x0 |
Posion Null Byte
Comparing two techniques about off-by-one null byte, house of einherjar seems not to suit for this case, so let’s play with poison null byte. Here’s an amazing blog about it: Posion null byte | Ret2Forever (also in Chinese), which makes me feel I have to borrow a picture from it.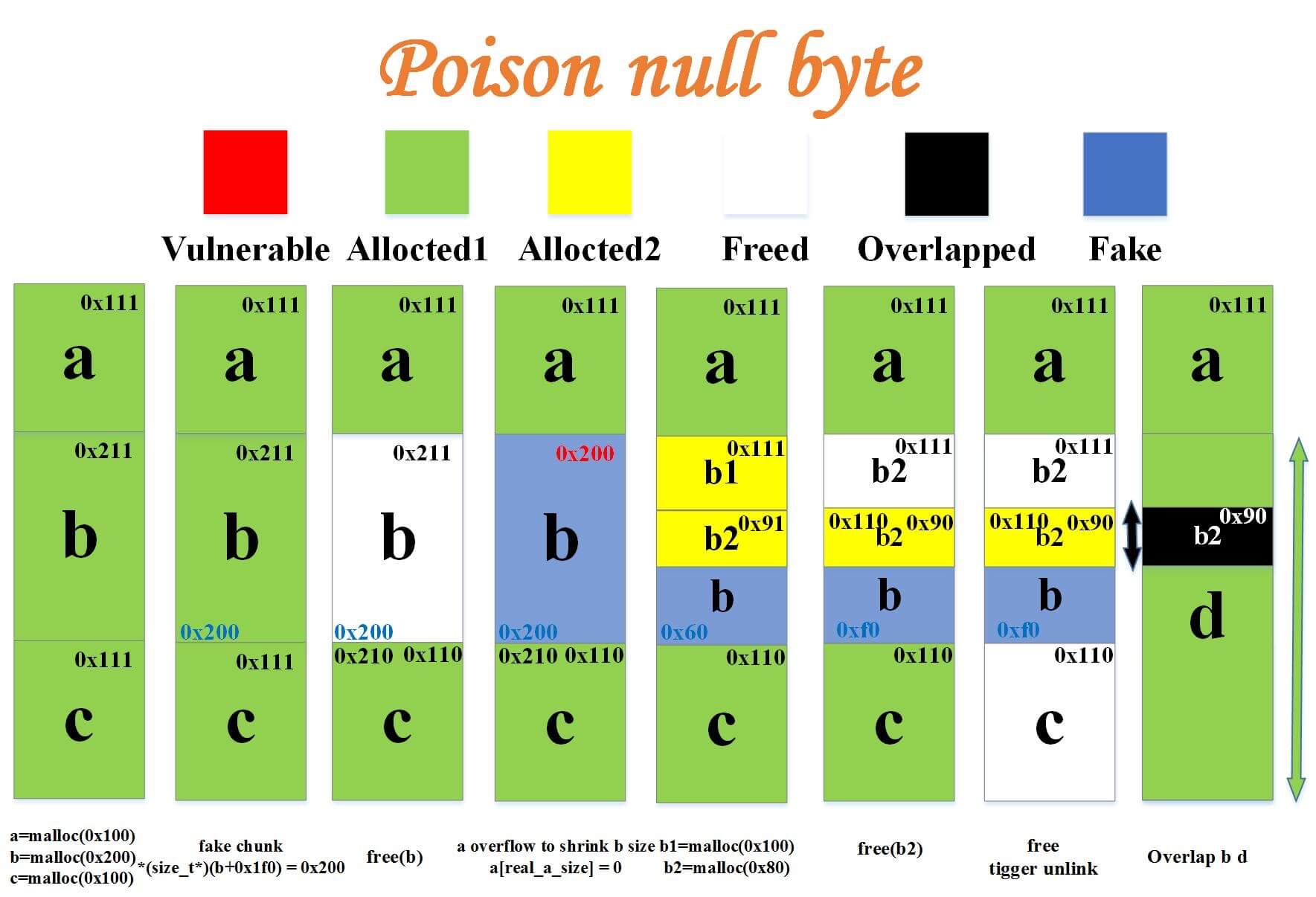 posionnullbyte
posionnullbyte
As the author concluded in this blog post, we need to allocate 3 chunks in this technique, name them a, b, c. Chunk a can be arbitrary size, but chunk b and c must not be fastbin size. Now we can make an unsorted bin to serve as chunk b, but what about chunk c? Does it have to be non-fastbin? No, the purpose of chunk c is to merge with chunk b and create a large chunk which overlap with some small chunks inside. So actually we can use the same trick in the last section to trigger malloc_consolidate and merge chunk b and c. Okey dokey, if we lay out the heap as it suggested, we can get the heap state like:
1 | (0x20) fastbin[0]: 0x0 |
and the item array is like:
1 | 0xc0e5acba260: 0x1 0x58 |
Now the large chunk in unsortedbin(0x555555578b10) is already overlap with item #6(0x555555578b40). Following job is straight-forward, just like baby heap 2018. We perform fastbin attack to get an item from the address in main_arena, then we change top chunk to somewhere before __malloc_hook, then we could overwrite __malloc_hook with one gadget. Btw, you have to turn on ASLR to complete fastbin attack on main_arena, and it only success when heap address starts with 0x56, otherwise the size check fails.
But unfortunately, all one gadget in libc-2.28 does not meet the requirement at the call:
1 | 0x50186 execve("/bin/sh", rsp+0x40, environ) |
@Tac1t0rnX also conclude some workaround for this situation here:
Pwnable.tw secretgarden
, I first try to write __malloc_hook to _libc_realloc+??? and __realloc_hook to one_gadget, but it also failed. So I have to turn to __free_hook trick, which overwrites top chunk to __free_hook - 0xb58, and allocate a bunch of junk chunk to reach __free_hook. To consume the top chunk and reach __free_hook buffer, we need to zero out the fastbin after each free. Here is my very first dirty exp used in the game.
Exp #1
1 | from pwn import * |
Better solution?
Actually, it wasted me a lot of time when debugging with the __free_hook trigger, so after the game, I wonder if there is any better way to call the one gadget? From the write up by r3kapig: here, I found they write __malloc_hook to svc_run+0x38 and __realloc_hook to one_gadget. svc_run+0x38 happen to be call realloc, with this additional call, it makes [rsp+0x40]==0 at the one gadget point.
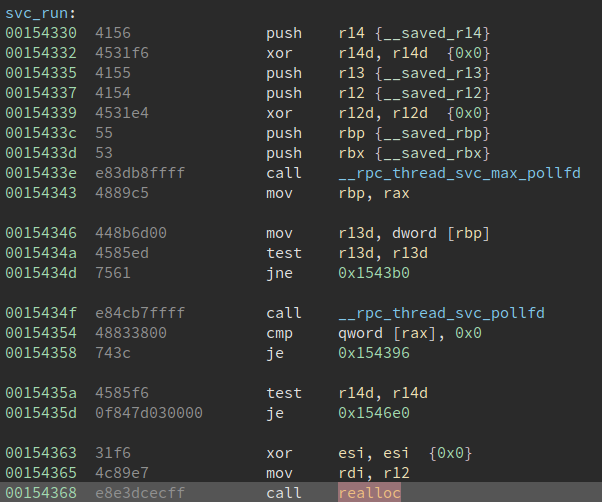 svc_run
svc_run
but it is still a coincidence, can we have something more general for similar situation? So I looked at every call realloc in libc-2.28.so, and finally found a perfect jump gadget. The gadget is at 0x105ae0, which can help to set [rsp+0x38] to 0, and then call realloc, when the program hit our one gadget point, [rsp+0x40] is exactly where we set 0 before!
So next time when you meet the situation in libc-2.28, feel confident to set __malloc_hook to libc+0x105ae0 and __realloc_hook to second one gadget.
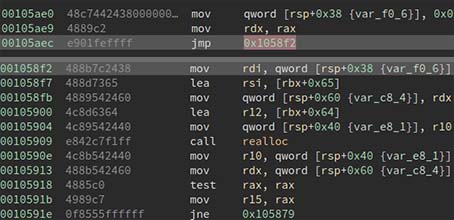 gadget
gadget
Here is my refined exp:
1 | from pwn import * |
Final words
With this challenage solved, our team ranked at 10th place in risingstar scoreboard. Thanks for @eee and @Oops for all great challenges, really enjoy the game! Wish our team can meet top players in Shanghai!